参考资料:https://www.runoob.com/w3cnote/ten-sorting-algorithm.html
概览
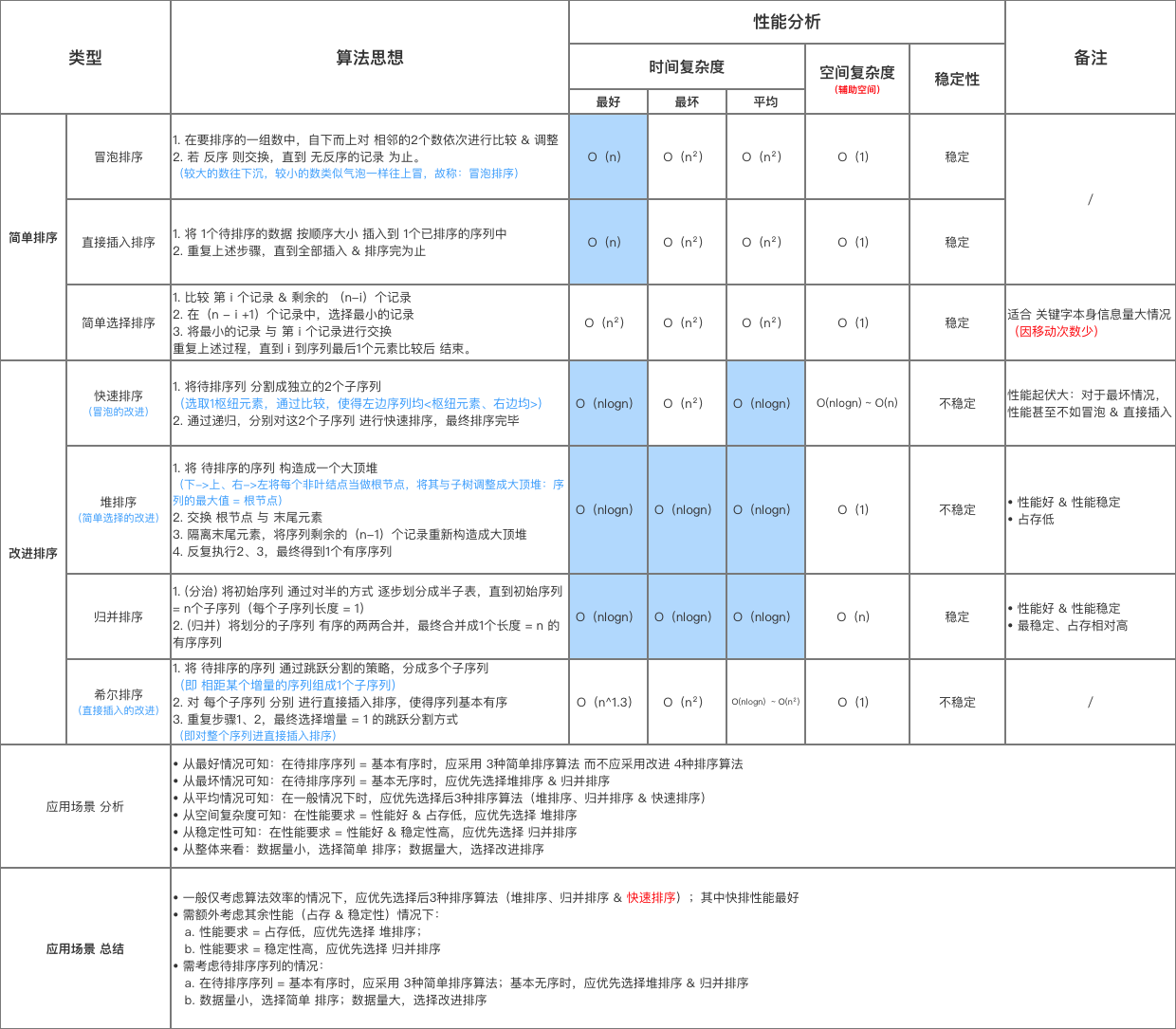
排序算法主要可根据 稳定性 、就地性 、自适应性 分类。理想的排序算法具有以下特性:
- 具有稳定性,即相等元素的相对位置不变化;
- 具有就地性,即不使用额外的辅助空间;
- 具有自适应性,即时间复杂度受元素分布影响。
冒泡排序
算法步骤:
- 比较相邻的元素。如果第一个比第二个大,就交换他们两个。
- 对每一对相邻元素作同样的工作,从开始第一对到结尾的最后一对。这步做完后,最后的元素会是最大的数。
- 针对所有的元素重复以上的步骤,除了最后一个。
- 持续每次对越来越少的元素重复上面的步骤,直到没有任何一对数字需要比较。
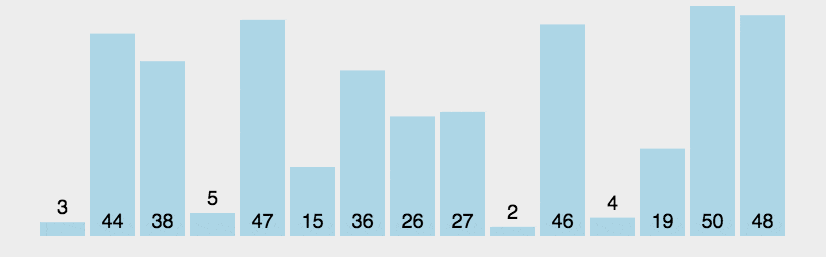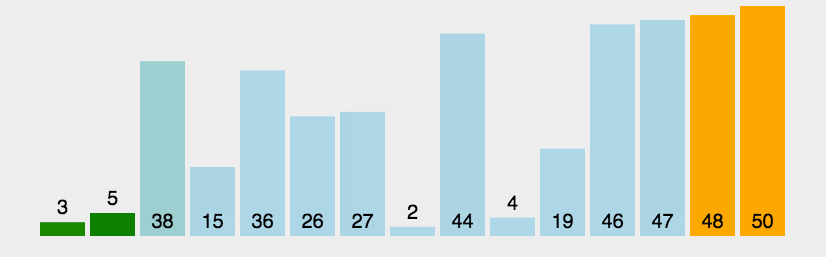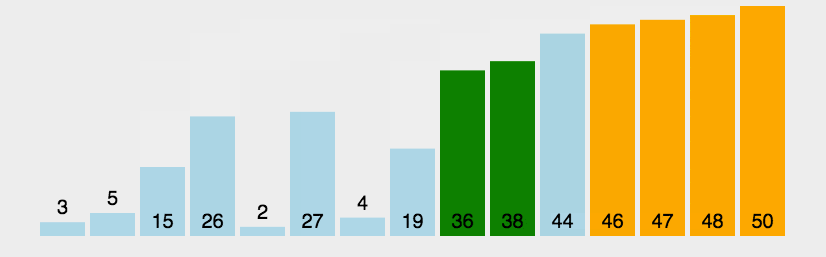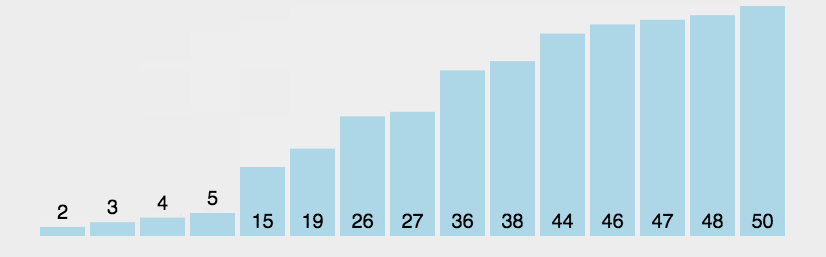
冒泡排序:
cpp
template <typename T>
void bubbleSort1(vector<T>& arr) {
for (int i = 0; i < arr.size(); ++i) {
for (int j = 0; j < arr.size() - i - 1; ++j) {
if (arr[j] > arr[j + 1]) {
swap(arr[j], arr[j + 1]);
}
}
}
}经过优化的写法:使用一个变量记录当前轮次的比较是否发生过交换,如果没有发生交换表示已经有序,不再继续排序。
cpp
template <typename T>
void bubbleSort2(vector<T>& arr) {
bool swapped = true;
for (int i = 0; i < arr.size(); ++i) {
if (!swapped) break; // 如果上一轮没有发生交换,则说明已经有序
swapped = false;
for (int j = 0; j < arr.size() - i - 1; ++j) {
if (arr[j] > arr[j + 1]) {
swap(arr[j], arr[j + 1]);
swapped = true;
}
}
}
}选择排序
算法步骤 首先在未排序序列中找到最小(大)元素,存放到排序序列的起始位置。 再从剩余未排序元素中继续寻找最小(大)元素,然后放到已排序序列的末尾。 重复第二步,直到所有元素均排序完毕。
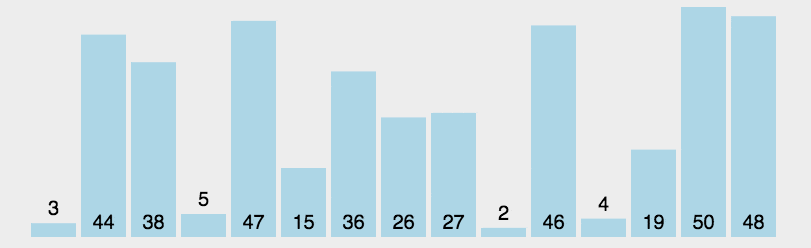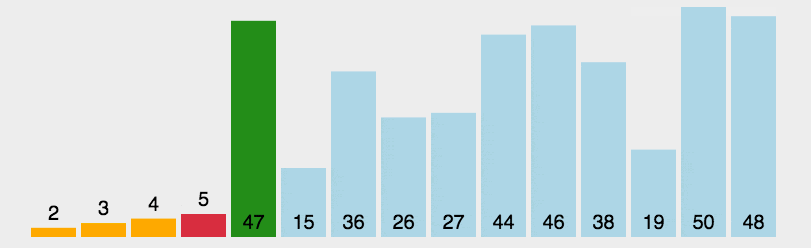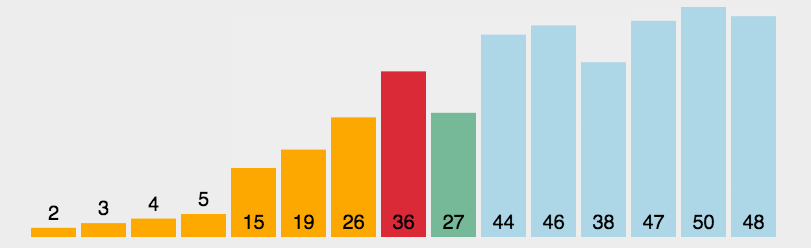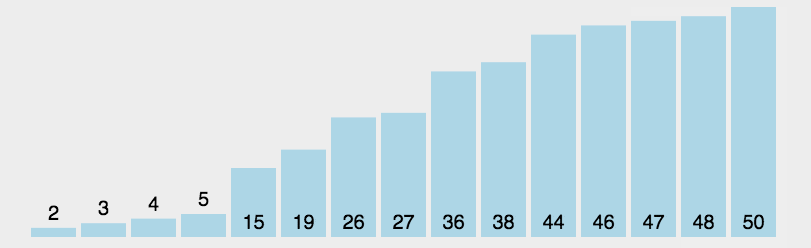
cpp
template <typename T>
void selectionSort(vector<T>& arr) {
for (int i = 0; i < arr.size(); ++i) {
int minIdx = i;
for (int j = i + 1; j < arr.size(); ++j) {
if (arr[minIdx] > arr[j]) {
minIdx = j;
}
}
swap(arr[i], arr[minIdx]);
}
}插入排序
算法步骤: 将第一待排序序列第一个元素看做一个有序序列,把第二个元素到最后一个元素当成是未排序序列。 从头到尾依次扫描未排序序列,将扫描到的每个元素插入有序序列的适当位置。(如果待插入的元素与有序序列中的某个元素相等,则将待插入元素插入到相等元素的后面。)
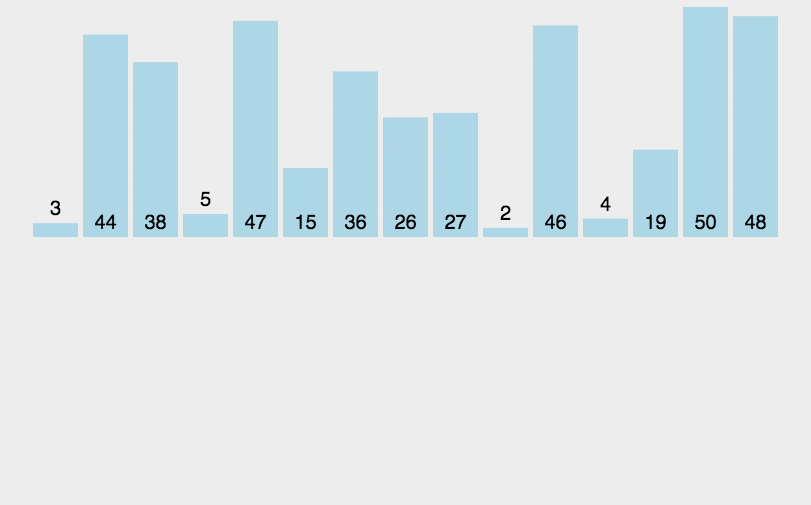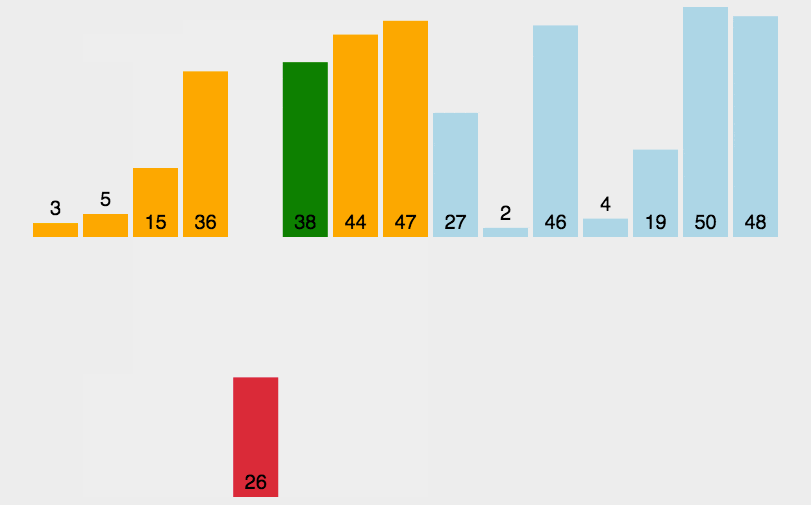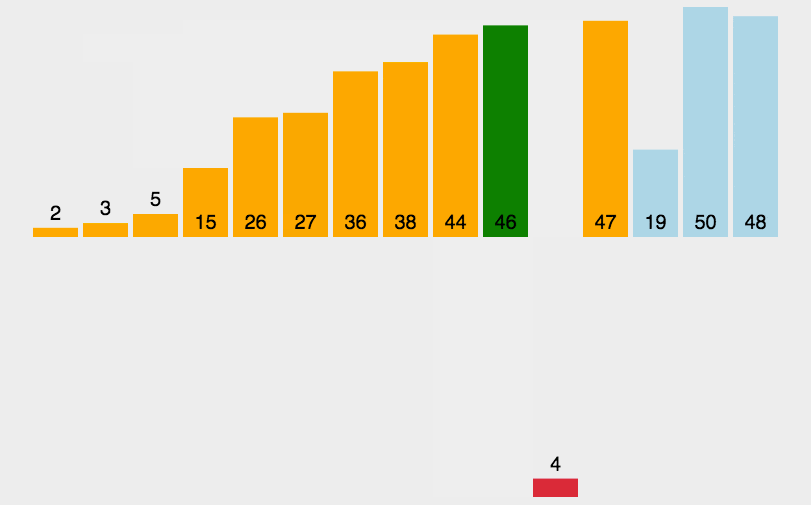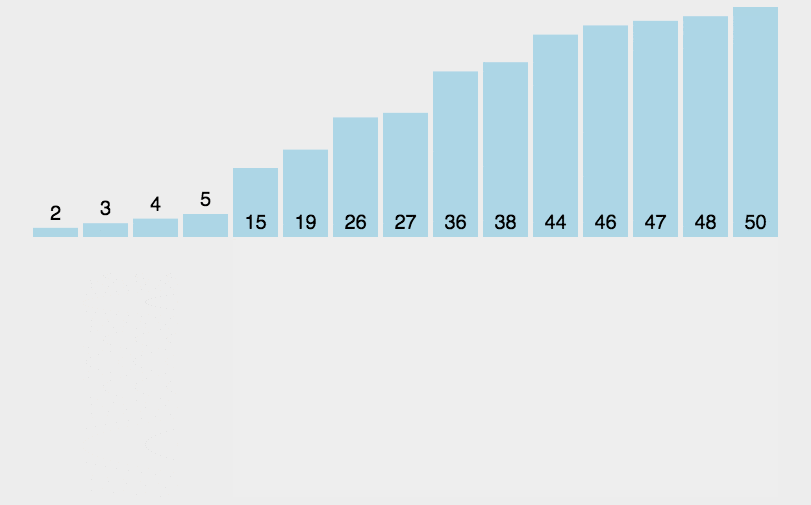
cpp
template<typename T>
void insertionSort(vector<T>& arr) {
for (int i = 1; i < arr.size(); ++i) {
int j = i - 1;
int key = arr[i];
while (j >= 0 && arr[j] > key)
{
arr[j + 1] = arr[j--];
}
arr[j + 1] = key;
}
}希尔排序
希尔排序,也称递减增量排序算法,是插入排序的一种更高效的改进版本。但希尔排序是非稳定排序算法。 希尔排序是基于插入排序的以下两点性质而提出改进方法的:
- 插入排序在对几乎已经排好序的数据操作时,效率高,即可以达到线性排序的效率;
- 但插入排序一般来说是低效的,因为插入排序每次只能将数据移动一位;
希尔排序的基本思想是:先将整个待排序的记录序列分割成为若干子序列分别进行直接插入排序,待整个序列中的记录“基本有序”时,再对全体记录进行依次直接插入排序。
算法步骤:
选择一个增量序列 t1, t2, ..., tk,其中 ti > tj, tk = 1;
按增量序列个数 k,对序列进行 k 趟排序;
每趟排序,根据对应的增量 ti,将待排序列分割成若干长度为 m 的子序列,分别对各子表进行直接插入排序。仅增量因子为 1 时,整个序列作为一个表来处理,表长度即为整个序列的长度。
cpp
// 希尔排序,优化版的插入排序
// 每次组内排序必须用插入排序或者冒泡排序(优化过的),插入排序和冒泡排序对“基本有序”的序列排序接近O(n)
template<typename T>
void shellSort(vector<T>& array) {
int gap = 1;
int n = array.size();
while (gap < n / 3) // 确定分组间隔
{
gap = gap * 3 + 1;
}
while (gap >= 1)
{
for (int i = gap; i < n; ++i) {
int key = array[i];
int j = i - gap;
while (j >= 0 && key < array[j])
{
array[j + gap] = array[j];
j -= gap;
}
array[j + gap] = key;
}
gap = gap / 3;
}
}归并排序
cpp
// 归并排序
template<typename T>
void mergeSort(vector<T> &vec, int left ,int right) {
if(left >= right)
return;
// 划分
int mid = (left + right) / 2;
mergeSort(vec, left, mid); // [l,mid] 有序
mergeSort(vec, mid + 1, right); // [mid+1,r] 有序
// 合并
vector<T> tmp(vec.begin()+left, vec.begin()+right + 1);
int i = 0;
int j = mid - left + 1;
for (int k = left; k <= right; ++k){
if(left + i > mid) {
vec[k] = tmp[j++];
} else if (left + j > right || tmp[i] <= tmp[j]) // <= 稳定
{
vec[k] = tmp[i++];
} else {
vec[k] = tmp[j++];
}
}
}快速排序
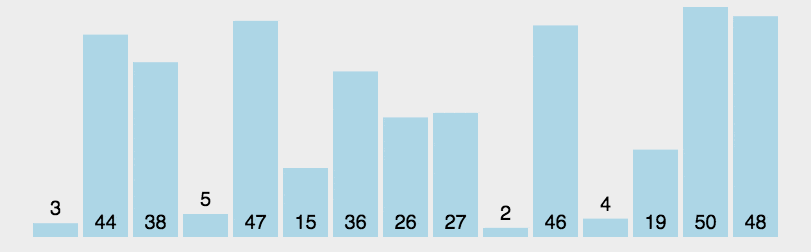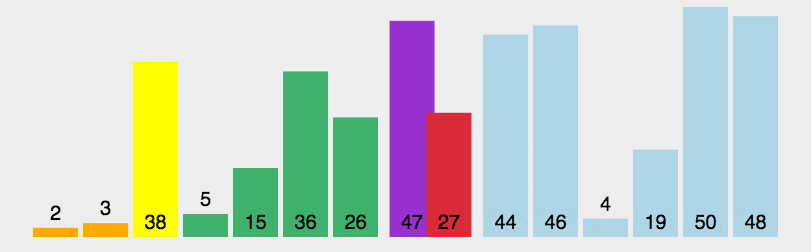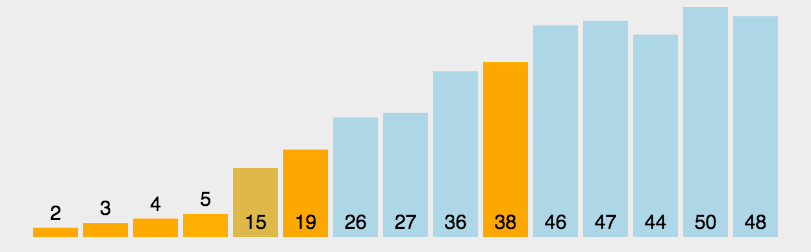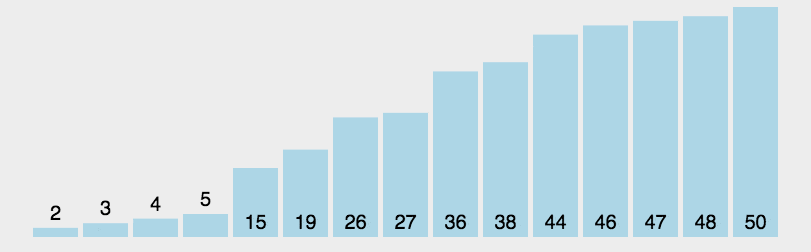
算法步骤:
- 从数列中挑出一个元素,称为 "基准"(pivot);
- 重新排序数列,所有元素比基准值小的摆放在基准前面,所有元素比基准值大的摆在基准的后面(相同的数可以到任一边)。在这个分区退出之后,该基准就处于数列的中间位置。这个称为分区(partition)操作;
- 递归地(recursive)把小于基准值元素的子数列和大于基准值元素的子数列排序;
cpp
template<typename T>
int partitionVec(vector<T> &vec, int l, int r) {
// 以 vec[l] 作为基准
int i = l;
int j = r;
while (i < j)
{
while (i < j && vec[j] >= vec[l])
--j;
while(i < j && vec[i] <= vec[l])
++i;
swap(vec[i], vec[j]);
}
swap(vec[l], vec[i]);
return i;
}
template <typename T>
void quickSort(vector<T> &vec, int l, int r) {
// 子数组的长度为 1 时终止递归
if(l >= r)
return;
// 哨兵划分
int pos = partitionVec(vec, l, r);
// 左右数组递归
quickSort(vec, l, pos - 1);
quickSort(vec, pos + 1, r);
}堆排序
堆排序(Heapsort)是指利用堆这种数据结构所设计的一种排序算法。堆积是一个近似完全二叉树的结构,并同时满足堆积的性质:即子节点的键值或索引总是小于(或者大于)它的父节点。堆排序可以说是一种利用堆的概念来排序的选择排序。分为两种方法:
- 大顶堆:每个节点的值都大于或等于其子节点的值,在堆排序算法中用于升序排列(递增数组);
- 小顶堆:每个节点的值都小于或等于其子节点的值,在堆排序算法中用于降序排列(递减数组)。
堆排序的平均时间复杂度为 $O(n\text{log}n)$。
算法步骤:
- 创建一个堆 H[0……n-1];
- 把堆首(最大值)和堆尾互换;
- 把堆的尺寸缩小 1,并调用 shift_down(0),目的是把新的数组顶端数据调整到相应位置;
- 重复步骤 2,直到堆的尺寸为 1。

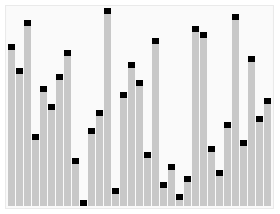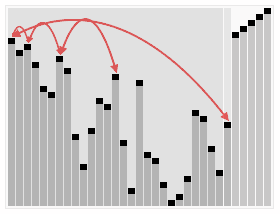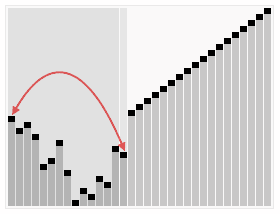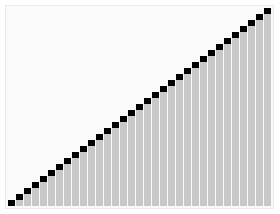
一般用数组存储堆结构:
下标为 $i$ 的节点的父节点下标为 $(i-1)/2$ ;
下标为 $i$ 的节点的左子节点下标为 $i \times 2 + 1$ ;
下标为 $i$ 的节点的右子节点下标为 $i \times 2 + 2$ 。
代码:
cpp
template <typename T>
void max_heapify(vector<T> &vec, int start, int end) {
int parent = start;
int child = parent * 2 + 1; // 左子节点下标
while (child <= end)
{
if(child + 1 <= end && vec[child] < vec[child + 1])
++child;
if (vec[parent] > vec[child]) {
return;
} else {
swap(vec[parent], vec[child]);
parent = child;
child = parent * 2 + 1;
}
}
}
template <typename T>
void heap_sort(vector<T> &vec) {
int len = vec.size();
for (int i = len / 2 - 1; i >= 0; --i) {
max_heapify(vec, i, len - 1); // 初始化堆,从最后一个根结点开始调整
}
for (int i = len - 1; i > 0; --i) {
swap(vec[0], vec[i]); // 将跟节点(最大元素)与最后一个元素交换
max_heapify(vec, 0, i - 1); // 将堆的尺寸缩小 1,再进行调整
}
}