报警触发
Prometheus周期计算配置的Rules的表达式(PromQL),若结果超过阈值并持续时长超过临界点,发送Alert到AlertManager。
指标的三种状态:
- inactive:没有触发阈值
- pending:已触发阈值但未满足告警持续时间
- firing:已触发阈值且满足告警持续时间
yaml
global:
# 默认每隔30秒执行一次表达式判断告警规则
evaluation_interval: 30s
rule_files:
# 表达式计算和记录,告警规则等自定义的配置文件
- /etc/prometheus-data/rules/*.yamlyaml
- alert: HostOutOfMemory
expr: node_memory_MemAvailable_bytes / node_memory_MemTotal_bytes * 100 < 10
for: 2m
labels:
severity: warning
annotations:
summary: Host out of memory (instance {{ $labels.instance }})
description: "Node memory is filling up (< 10% left)\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
- alert: xxx
expr: xxx
for: xxx
labels:
severity: xxx
annotations:
summary: xxx
description: xxxGo
// Alert is a generic representation of an alert in the Prometheus eco-system.
type Alert struct {
// Label value pairs for purpose of aggregation, matching, and disposition
// dispatching. This must minimally include an "alertname" label.
Labels LabelSet `json:"labels"`
// Extra key/value information which does not define alert identity.
Annotations LabelSet `json:"annotations"`
// The known time range for this alert. Both ends are optional.
StartsAt time.Time `json:"startsAt,omitempty"`
EndsAt time.Time `json:"endsAt,omitempty"`
GeneratorURL string `json:"generatorURL"`
}
type LabelSet map[LabelName]LabelValue报警管理
Promethues根据配置的策略决定是否需要触发告警,如需告警则根据配置的路由链路依次发送告警。
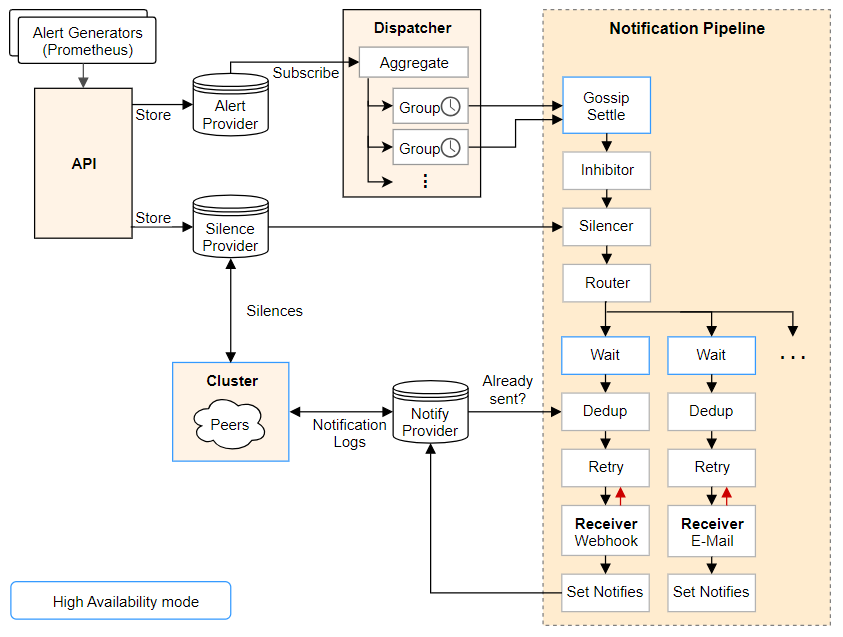
- 从左上开始,Prometheus 发送的警报到 Alertmanager;
- 警报会被存储到 AlertProvider 中(本机内存);
- Dispatcher 是一个单独的 goroutine,它会不断到 AlertProvider 拉新的警报,并且根据 YAML 配置的
Routing Tree将警报路由到一个分组中; - 分组会定时进行 flush (间隔为配置参数中的 group_interval), flush 后这组警报会走一个
Notification Pipeline链式处理; Notification Pipeline为这组警报确定发送目标,并执行抑制逻辑,静默逻辑,去重逻辑,发送与重试逻辑,实现警报的最终投递;
Routing Tree
Routing Tree 的是一颗多叉树,警报从 root 开始匹配(root 默认匹配所有警报),然后根据节点中定义的 Matchers 检测警报与节点是否匹配,匹配则继续往下搜索,默认情况下第一个”最深”的 match (也就是 DFS 回溯之前的最后一个节点)会被返回。
yaml
[ receiver: <string> ]
[ group_by: '[' <labelname>, ... ']' ]
[ continue: <boolean> | default = false ]
match:
[ <labelname>: <labelvalue>, ... ]
match_re:
[ <labelname>: <regex>, ... ]
[ group_wait: <duration> | default = 30s ]
[ group_interval: <duration> | default = 5m ]
[ repeat_interval: <duration> | default = 4h ]
routes:
[ - <route> ... ]Notification Pipeline
由 Routing Tree 分组后的警报会触发 Notification Pipeline:
- 当一个 AlertGroup 新建后,它会等待一段时间(group_wait 参数),再触发第一次 Notification Pipeline
- 假如这个 AlertGroup 持续存在,那么之后每隔一段时间(group_interval 参数),都会触发一次 Notification Pipeline
每次触发 Notification Pipeline,AlertGroup 都会将组内所有的 Alert 作为一个列表传进 Pipeline, Notification Pipeline 本身是一个按照责任链模式设计的接口,MultiStage 会链式执行所有的 Stage。
Notification Pipeline通过一系列逻辑(如抑制、静默、去重)来获得更高的警报质量,由于警报质量的维度很多(剔除重复、类似的警报,静默暂时无用的警报,抑制级联警报),因此 Notification Pipeline 设计成了责任链模式,以便于随时添加新的环节来优化警报质量
调研demo运行 功能开发 测试